Robots' ability to follow language instructions and execute diverse 3D manipulation tasks is vital in robot learning. Traditional imitation learning-based methods perform well on seen tasks but struggle with novel, unseen ones due to variability. Recent approaches leverage large foundation models to assist in understanding novel tasks, thereby mitigating this issue. However, these methods lack a task-specific learning process, which is essential for an accurate understanding of 3D environments, often leading to execution failures. In this paper, we introduce GravMAD, a sub-goal-driven, language-conditioned action diffusion framework that combines the strengths of imitation learning and foundation models. Our approach breaks tasks into sub-goals based on language instructions, allowing auxiliary guidance during both training and inference. During training, we introduce Sub-goal Keypose Discovery to identify key sub-goals from demonstrations. Inference differs from training, as there are no demonstrations available, so we use pre-trained foundation models to bridge the gap and identify sub-goals for the current task. In both phases, GravMaps are generated from sub-goals, providing GravMAD with more flexible 3D spatial guidance compared to fixed 3D positions. Empirical evaluations on RLBench show that GravMAD significantly outperforms state-of-the-art methods, with a 28.63% improvement on novel tasks and a 13.36% gain on tasks encountered during training. Evaluations on real-world robotic tasks further show that GravMAD can reason about real-world tasks, associate them with relevant visual information, and generalize to novel tasks. These results demonstrate GravMAD's strong multi-task learning and generalization in 3D manipulation.
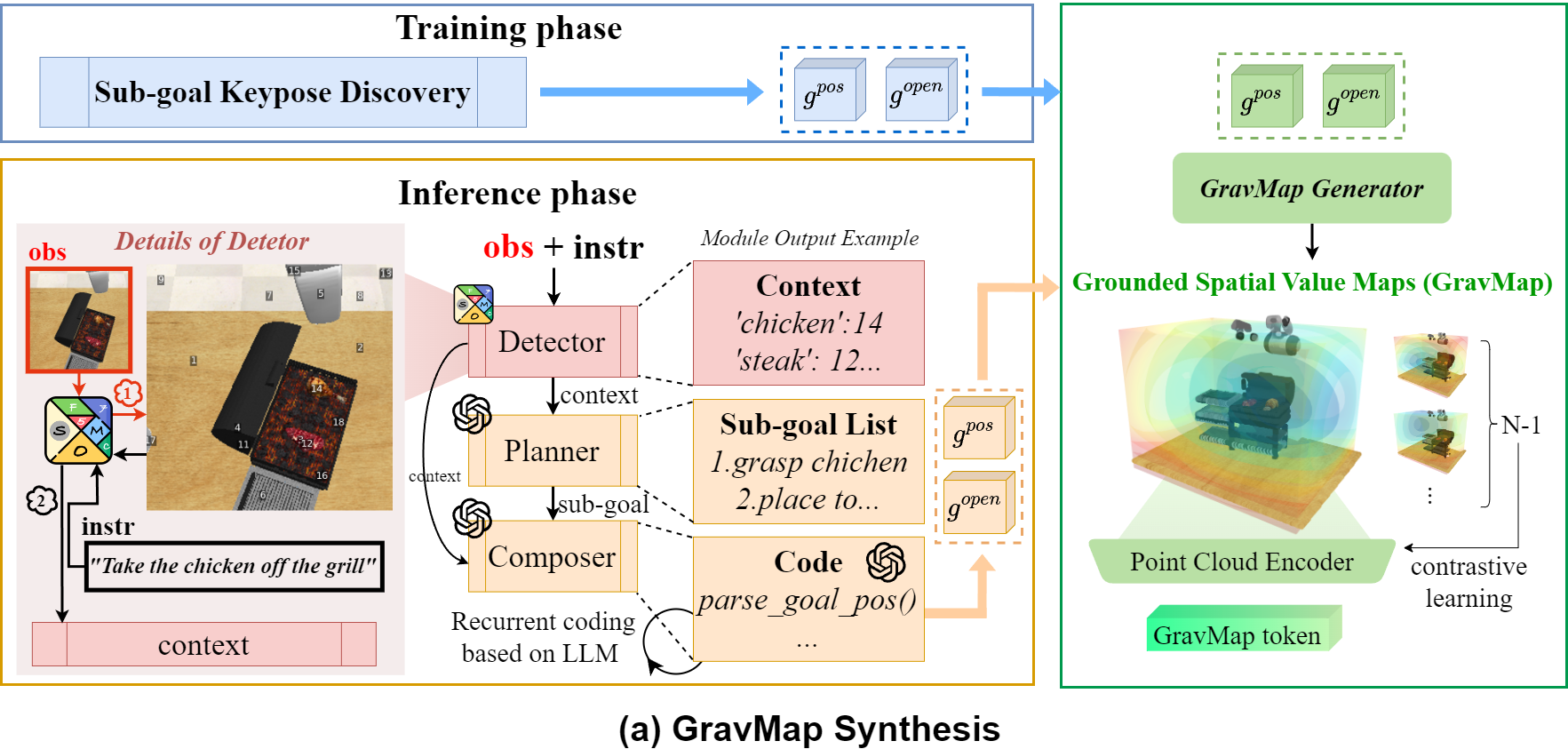
(a) GravMap Synthesis: During training, we use Sub-goal Keypose Discovery to obtain sub-goals $g^\text{pos}$ and $g^\text{open}$. During inference, the Detector, Planner, and Composer pipeline interprets visual observations and language instructions to derive $g^\text{pos}$ and $g^\text{open}$, which are processed into a GravMap and encoded as a GravMap token.
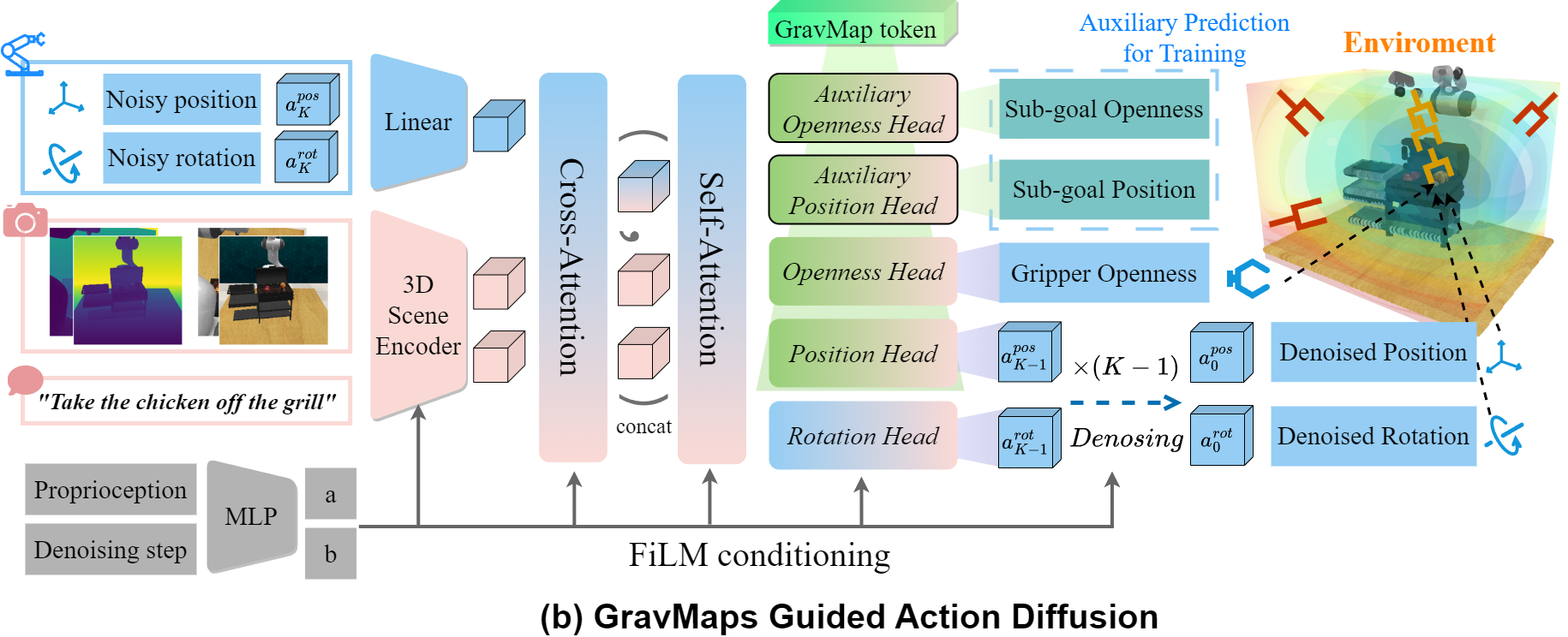
(b) GravMaps Guided Action Diffusion: The policy network perceives the scene and denoises noisy actions guided by the GravMap token. After $K$ denoising steps, the clean actions are executed by the robot.
Interactive GravMap 1
Interactive GravMap 2
Prompts in Simulation Environments:
Base tasks |
Novel tasks
@article{chen2024gravmad,
title={GravMAD: Grounded Spatial Value Maps Guided Action Diffusion for Generalized 3D Manipulation},
author={Chen, Yangtao and Chen, Zixuan and Yin, Junhui and Huo, Jing and Tian, Pinzhuo and Shi, Jieqi and Gao, Yang},
journal={arXiv preprint arXiv:2409.20154},
year={2024}
} ,
,